
随着全球经济日益紧密,全球企业正在以前所未有的速度发展。为了更好地理解这一趋势,Morketing Research特别推出了一档栏目「全球企业情报帖」。
在本栏目中,我们将深入搜寻全球企业的最新动态,带大家了解更多企业,一同见证世界各地的商业脉搏跳动。
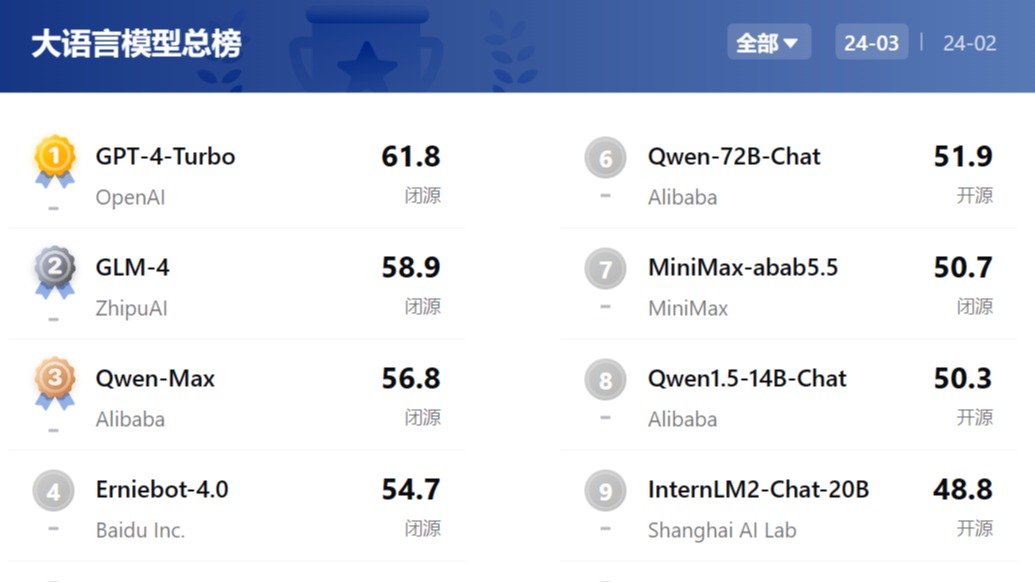
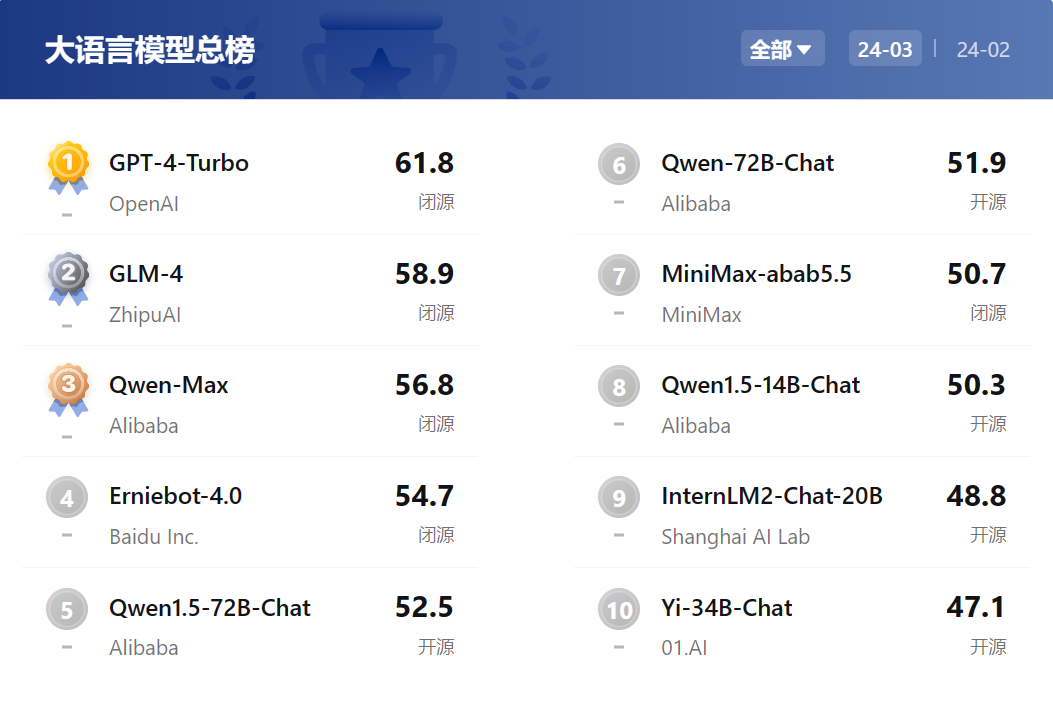
大模型开源开放评测体系司南(OpenCompass2.0)最近更新了大模型评测排行,通过对国内外主流大模型的全面评测诊断,全面量化模型在知识、语言、理解、推理和考试等五大能力的表现。OpenCompass2.0的评测维度包括基础能力和综合能力两个层级,涵盖了语言、知识、理解、数学、代码、长文本、智能体等12个一级能力维度,综合设计了50余个二级能力维度。在最近更新的大语言模型中英双语客观评测排行中,OpenAI研发的GPT-4 Turbo位居第一,紧随其后的分别是智谱AI的GLM-4、阿里巴巴Qwen-Max、百度文心一言4.0、阿里巴巴Qwen1.5-72B-Chat,占据了排行榜的前五名。OpenCompass2.0 大语言模型中英双语客观评测 Top10此外,OpenCompass2.0 在对过去一年来主流开源模型和商业API模型的全面评测分析中得到了一些观察和总结:
- 大语言模型整体能力仍有较大提升空间:由于采用了更加准确的循环评测策略,OpenCompass2.0实现了对模型真实能力分析。在百分制的客观评测基准中,GPT-4 Turbo也仅达到61.8分的及格水平。此结果显示,复杂推理仍然是大模型面临的重要难题,需要进一步的技术创新来攻克。
- 闭源商业模型主客观能力均衡:在综合性客观评测中,智谱清言GLM-4、阿里巴巴Qwen-Max和百度文心一言4.0也获得了不错的成绩,反映了这些模型具有较为均衡和全面的性能。上述模型在语言和知识等基础能力维度上可以比肩GPT-4 Turbo。
- 推理、数学、代码、智能体是国内大模型的短板:GPT-4 Turbo在涉及复杂推理的场景虽然亦有提升空间,但已明显领先于国内的商业模型和开源模型。国内大模型要整体赶超GPT-4 Turbo等国际顶尖的大模型,在复杂推理、可靠地解决复杂问题等方面,仍需下大功夫。
- 主客观性能需综合参考:不少开源模型在客观性能和主观性能方面和API模型仍存在相当程度的差距,这说明整个社区不仅需要提升客观性能夯实能力基础,更需要在人类偏好对齐上下足功夫。合理科学地使用评测基准,对模型能力进行细致对比和分析,是模型厂商不断提升模型能力的不二法门。
- 国内模型在中文场景下相比海外模型具有性能优势:在中文语言理解、中文知识和中文创作上,国内商业模型相比 GPT-4 Turbo 具有极强的竞争力,甚至部分模型实现了单个维度上对 GPT-4 Turbo 的超越。
- 中文闭源大语言模型接近GPT-4 Turbo水平:不少国内厂商近期新发布的模型在多个能力维度上正在快速缩小与GPT-4 Turbo的差距,阿里巴巴Qwen-Max、智谱清言 GLM-4、百度文心4.0都取得了优秀的成绩;期待随着更多厂商的新模型发布,赶超GPT-4 Turbo迈出更坚实的步伐。
- 开源社区未来可期:开源社区的Yi-34B-Chat、InternLM2-Chat-20B在综合性对话体验上达到了所有主流开源模型的第一梯度,并以中轻量级的参数量、接近商业闭源模型的性能,为学界和业界提供了良好的应用基础。
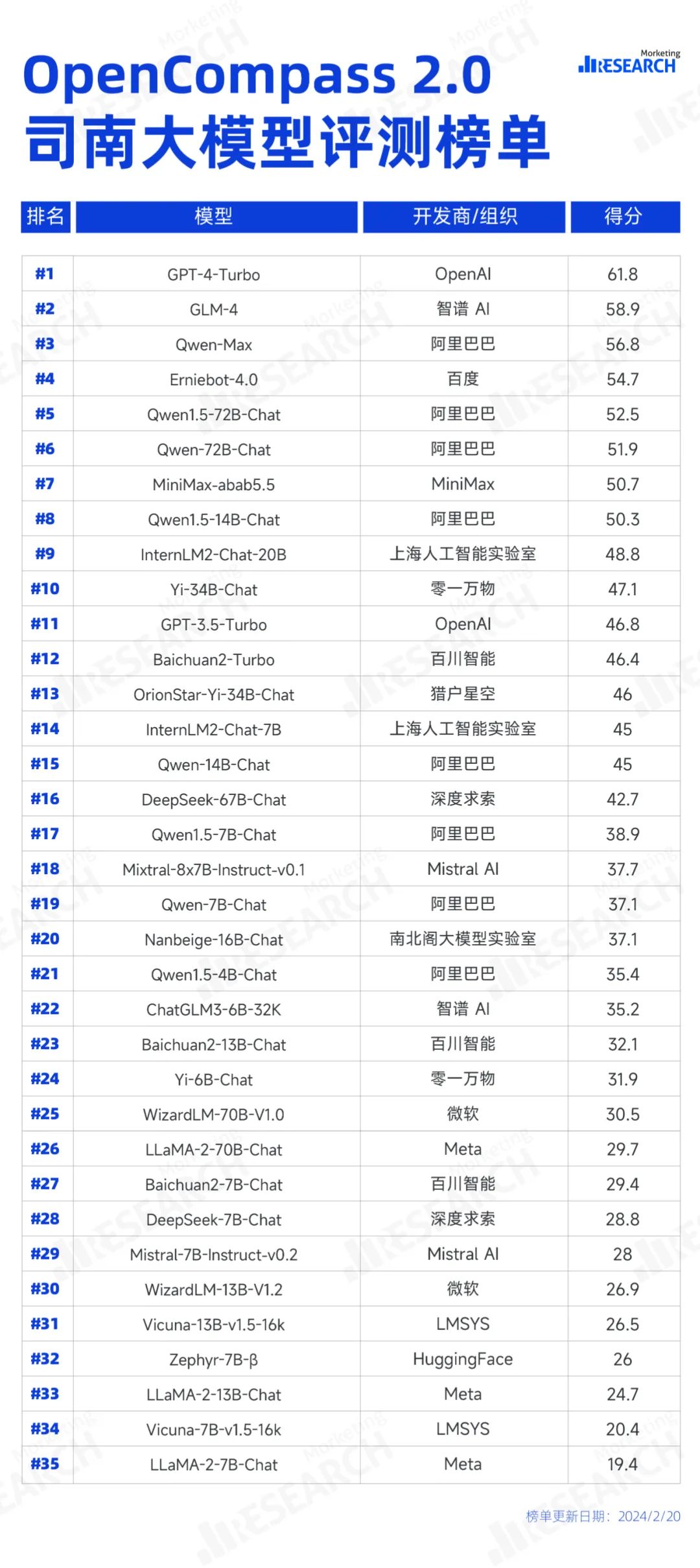
完整 OpenCompass 2.0 司南大模型评测榜单如下:


 手机号码错误
手机号码错误






